The project aimed to implement a method which predicts the sentiment(s) of given text data.
In implementation:
- Sentiments were limited to two i.e. positive and negative.
- Text (training)data was composed of movie reviews downloaded from here (page on www.cs.cornell.edu).
- The training data’s size was rather small, only 2000 records were available, 1000 of each polarity, which were further reduced as 10-30 % of data was seperated for testing/cross validation.
Methods of Natural Language Programming along Machine Learning were used, brief details about them are as follows:
- Language Model: Bigram Frequencies, since bigrams are composed of adjacent words, this model does not take into account the relationship between words which are farther apart in sentence.
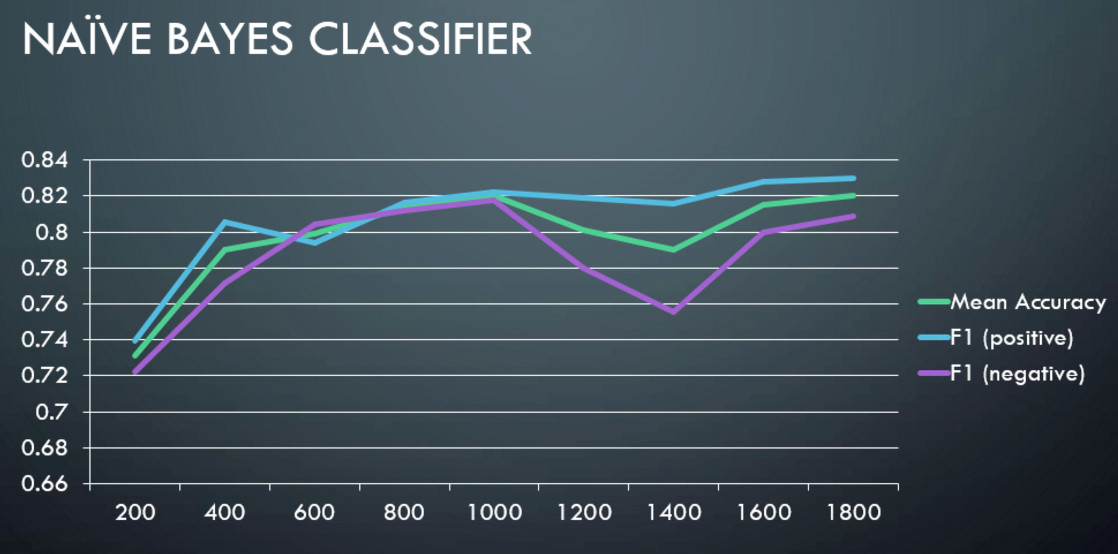
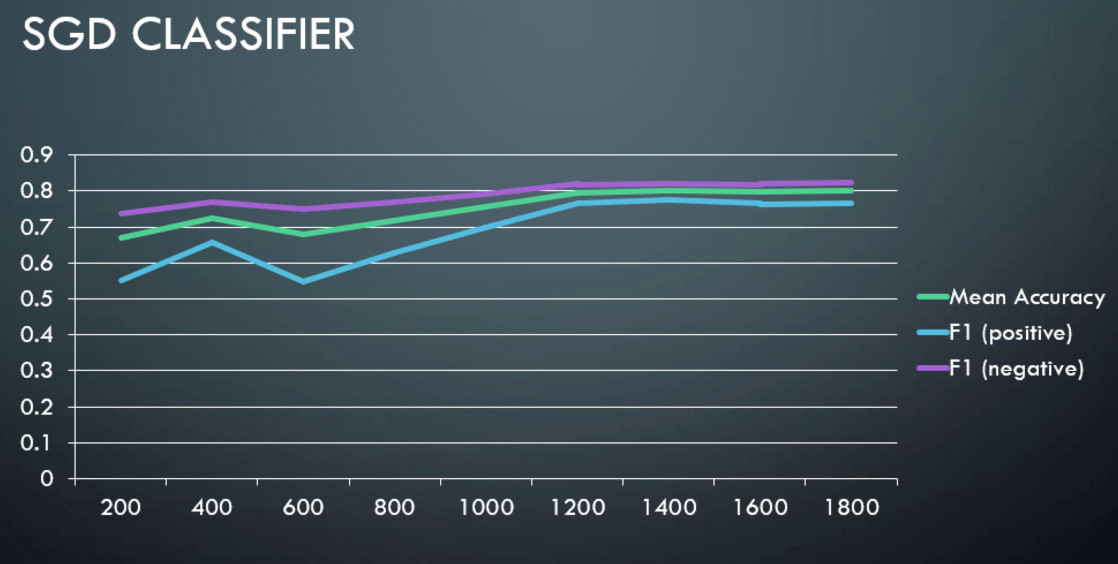
- Classifiers: Multinomial Naive Bayesian (maximum likelihood approach) and Stochastic Gradient Descent.
- scikit-learn was used in the implementation.
The graphs below shows mean accuracy, F1 score of positive and negative class vs the number of records used for training.
There is lot of scope of improvement in projects, two important aspects which needs to be improved are more training data and increase in the range of sentiments.